-
부스트캠프 ai tech 2기 1주차 학습 정리 노트Boostcamp AI Tech 2기 2021. 8. 4. 16:47
강의 복습
Python 2-1
변수 : 데이터(값)을 저장하기 위한 메모리 공간의 프로그래밍상 이름
변수는 메모리 주소를 가지고 있고 변수에 들어가는 값은 메모리 주소에 할당된다.
피연산자(operand) : 연산자(operator)에 의해 계산이 되는 숫자들
*이차원 이상의 리스트를 복사할 땐 copy 모듈의 deepcopy를 이용하자!
Python 2-2
함수 : 어떤 일을 수행하는 코드의 덩어리
캡슐화 : 인터페이스만 알면 타인의 코드를 사용할 수 있는 함수의 특성이다.
parameter : 함수의 입력 값 인터페이스. def func(x)의 x에 해당하는 부분.
argument : 실제 parameter에 대입된 값. print(f(2))의 2에 해당하는 부분.
Python 2-3
조건문 : 조건에 따라 특정한 동작을 하게 하는 명령어. 조건을 나타내는 기준과 실행해야할 명령으로 구성된다.
삼항 연산자(Ternary operators) : 조건문을 사용하여 참일 경우와 거짓인 경우의 결과를 한줄에 표현한 것. ex) is_even = True if value % 2 == 0 else False
반복문 : 정해진 동작을 반복적으로 수행하게 하는 명령문. 반복 시작 조건, 종료 조건, 수행 명령으로 구성된다.
*반복문의 끝에 else구문을 넣으면 반복 종료 후 else문 내의 명령이 1회 수행되며, break로 종료된 반복문은 else block이 수행되지 않는다!
Python 2-4
문자열(string) : 시퀀스 자료형으로 문자형 data를 메모리에 저장한다. 영문자 한 글자는 1byte = 8bit의 메모리 공간을 사용한다.
Call by Value : 함수에 인자를 넘길 때 값만 넘긴다. 함수 내에 인자 값 변경시, 호출자에게 영향을 주지 않는다.
Call by Reference : 함수에 인자를 넘길 때 메모리 주소를 넘긴다. 함수 내에 인자 값 변경시, 호출자의 값도 변경된다.
지역변수(Local variable) : 함수내에서만 사용
전역변수(Global variable) : 프로그램전체에서 사용
함수 작성 가이드 라인
- 가능하면 짧게
- 함수 이름에 함수의 역할, 의도가 명확히 들어낼 것
- 하나의 함수에는 유사한 역할을 하는 코드만 포함할 것
- 인자로 받은 값 자체를 바꾸진 말 것 (임시변수 선언)
Python 3-1
스택(Stack) : 나중에 넣은 데이터를 먼저 반환하도록 설계된 메모리 구조(Last In First Out). Data의 입력을 Push, 출력을 Pop이라고 한다.
큐(Queue) : 먼저 넣은 데이터를 먼저 반환하도록 설계된 메모리 구조(First In First Out).
튜플(Tuple) : 값의 변경이 불가능한 리스트. 리스트의 연산, 인덱싱, 슬라이싱 등을 동일하게 사용한다.
집합(Set) : 값을 순서없이 저장하고 중복을 불허하는 자료형. 수학에서 사용하는 다양한 집합 연산이 가능하다.
사전(Dictionary) : 데이터(value)를 저장 할 때 구분 지을 수 있는 값(key)을 함께 저장한다. {Key1:Value1, Key2:Value2, Key3:Value3 ...}의 형태이다.
collections 모듈
- deque : Stack과 Queue 를 지원하는 모듈
- defaultdict : Dict type의 값에 기본 값을 지정하여 신규값 생성시 사용하는 방법
- Counter : Sequence type의 data element들의 갯수를 dict 형태로 반환한다. set 연산을 지원한다.
- namedtuple : Tuple 형태로 Data 구조체를 저장하는 방법. 저장되는 data의 variable을 사전에 지정해서 저장한다.
Python 3-2
split : string type의 값을 “기준값”으로 나눠서 List 형태로 변환
join : string으로 구성된 list를 합쳐 하나의 string으로 반환
list comprehension : 기존 List를 사용하여 간단히 다른 List를 만드는 기법. 일반적으로 for + append 보다 속도가 빠름 ex) result = [i for i in range(10)]
enumerate : list의 element를 추출할 때 번호를 붙여서 추출
zip : 두 개의 list의 값을 병렬적으로 추출
lambda : 함수 이름 없이, 함수처럼 쓸 수 있는 익명함수. Python 3부터는 권장하지는 않으나 여전히 많이 쓰인다.
map : 이터러블한 자료구조 내부 각각의 요소에 공통된 함수를 적용
reduce : map function과 달리 list에 똑같은 함수를 적용해서 통합
iterable object : - Sequence형 자료형에서 데이터를 순서대로 추출하는 object. 내부적 구현으로 __iter__ 와 __next__ 가 사용되며 iter() 와 next() 함수로 iterable 객체를 iterator object로 사용한다.
generator : iterable object를 특수한 형태로 사용해주는 함수. element가 사용되는 시점에 값을 메모리에 반환한다. yield를 사용해 한번에 하나의 element만 반환.
가변 인자(variable-length) : 개수가 정해지지 않은 변수를 함수의 parameter로 사용하는 법. Asterisk(*) 기호를 사용하여 함수의 parameter를 표시한다. 입력된 값은 tuple type으로 사용할 수 있다.
키워드 가변 인자(Keyword variable-length) : Parameter 이름을 따로 지정하지 않고 입력하는 방법. asterisk(*) 두개를 사용하여 함수의 parameter를 표시한다. 입력된 값은 dict type으로 사용할 수 있다.
Python 4-1
객체 : 실생활 속 일종의 물건. 속성(Attribute)와 행동(Action)을 가진다.
OOP는 이러한 객체 개념을 프로그램으로 표현한 것으로, 속성은 변수(Variable), 행동은 함수(method)로 표현된다.
Attribute 추가는 __init___ , self와 함께한다. __init__은 객체 초기화 예약 함수다.
__는 특수한 예약 함수나 변수 그리고 함수명 변경(맨글링)으로 사용한다. ex) __main__ , __add__ , __str__ , __eq__
상속(Inheritance) : 부모클래스로 부터 속성과 Method를 물려받은 자식 클래스를 생성 하는 것
다형성(Polymorphism) : 같은 이름 메소드의 내부 로직을 다르게 작성
가시성(Visibility) : 객체의 정보를 볼 수 있는 레벨을 조절하는 것
일급 객체(First-class objects) : 변수나 데이터 구조에 할당이 가능한 객체로, 파라메터로 전달이 가능하며 리턴 값으로 사용한다.
Inner function : 함수 내에 또 다른 함수가 존재
Python 4-2
모듈(Module) : == py파일. import문을 통해 호출한다.
Built-in Modules : 파이썬이 기본 제공하는 라이브러리. 문자처리, 웹, 수학 등 다양한 모듈이 제공된다.
패키지(Package) : 하나의 대형 프로젝트를 만드는 코드의 묶음. 다양한 모듈의 합, 폴더로 연결된다. __init__ , __main__ 등 키워드 파일명이 사용된다. 다양한 오픈 소스들이 모두 패키지로 관리된다.
Python 5-1
Built-in Exception: 기본적으로 제공하는 예외
- Index Error : List의 Index 범위를 넘어갈 때
- NameError : 존재하지 않은 변수를 호출할 때
- ZeroDivisionError : 0으로 숫자를 나눌 때
- ValueError : 변환할 수 없는 문자/숫자를 변환할 때
- FileNotFoundError : 존재하지 않는 파일을 호출할 때
디렉토리 : 폴더로도 불린다. 파일과 다른 디렉토리를 포함할 수 있다.
파일 : 컴퓨터에서 정보를 저장하는 논리적인 단위. 파일은 파일명과 확장자로 식별된다. 실행, 쓰기, 읽기 등을 할 수 있다.
configparser : 프로그램의 실행 설정을 file에 저장. Section, Key, Value 값의 형태로 설정된 설정 파일을 사용한다. 설정파일을 Dict Type으로 호출후 사용한다.
argparser : Console 창에서 프로그램 실행시 Setting 정보를 저장. 거의 모든 Console 기반 Python 프로그램에서 기본으로 제공한다. Command-Line Option 이라고 부른다.
Python 5-2
CSV(Comma Seperate Value) : 필드를 쉼표(,)로 구분한 텍스트 파일. 액셀 형식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식이다.
Web : 우리가 사용하는 인터넷 공간. 데이터 송수신을 위한 HTTP 프로토콜을 사용하며 데이터를 표시하기 위해 HTML 형식을 사용한다.
HTML(Hyper Text Markup Language) : 웹 상의 정보를 구조적으로 표현하기 위한 언어. 제목, 단락, 링크 등 요소 표시를 위해 Tag를 사용한다. 모든 HTML은 트리 모양의 포함관계를 가지며 모든 요소들은 꺾쇠 괄호 안에 둘러 쌓여 있다. ex) <title> Hello, World </title>
정규식(regular expression) : 정규 표현식, regexp 또는 regex 등으로 불린다. 복잡한 문자열 패턴을 정의하는 문자 표현 공식으로, 특정한 규칙을 가진 문자열의 집합을 추출한다. 파이썬에서는 re 모듈을 import 하여 사용한다.
XML : re 모듈을 import하여 사용데이터의 구조와 의미를 설명하는 TAG(MarkUp)를 사용하여 표시하는 언어. TAG와 TAG사이에 값이 표시되고, 구조적인 정보를 표현할 수 있다. XML도 HTML과 같이 구조적 markup 언어로, 정규표현식으로 Parsing이 가능하다.
BeautifulSoup : HTML, XML등 Markup 언어 Scraping을 위한 대표적인 도구. 파이썬에서는 from bs4 import BeautifulSoup을 통해 사용한다.
JSON(JavaScript Object Notation) : 원래 웹 언어인 Java Script의 데이터 객체 표현 방식. 간결성으로 인해 기계/인간이 모두 이해하기 편하며 데이터 용량이 적고, Code로의 전환이 쉽다. 웹에서 제공하는 API는 대부분 정보 교환 시 JSON 활용하며, 파이썬에서는 json 모듈을 사용하여 손 쉽게 파싱 및 저장이 가능하다. 또한 데이터 저장 및 읽기는 dict type과 상호 호환 가능하다.
Python 6
Numpy : 파이썬의 고성능 과학 계산용 패키지. Matrix, Vector와 같은 Array연산의 표준 라이브러리이다. 일반 리스트에 비해 빠르고, 메모리의 측면에서 효율적이며 반복문 없이 데이터 배열에 대한 처리를 지원한다. 또한 선형대수와 관련된 다양한 기능을 제공하며 C, C++, 포트란 등의 언어와도 통합가능하다.
Python 7-1
Pandas : 구조화된 데이터의 처리를 지원하는 파이썬 라이브러리. 인덱싱, 연산용함수, 전처리함수 등을제공하며 데이터처리 및 통계분석을 위해 사용한다.
Python 7-2
Groupby : SQL groupby 연산과 같다. split -> apply -> combine 과정을 거쳐 연산한다.
grouped : Groupby에 의해 Split된 상태를 추출 가능하다. 추출된 group 정보에는 3가지 유형의 apply가 가능하다.
- Aggregation: 요약된 통계정보를 추출
- Transformation: 해당 정보를 변환
- Filtration: 특정 정보를 제거 하여 보여주는 필터링 기능
Crosstab : Pivot table의 특수한 형태로, 두 칼럼에 교차 빈도, 비율, 덧셈 등을 구할 때 사용한다. User-Item Rating Matrix 등을 만들 때 사용가능하다.
merge : 두 개의 데이터를 하나로 합친다.
concat : 같은 형태의 데이터를 붙이는 연산 작업.
AI Math 1
벡터 : 숫자를 원소로 가지는 리스트 또는 배열. 공간에서 한 점을 나타내며, 원점으로부터의 상대적 위치를 표현한다. 벡터에 숫자를 곱해주면 길이만 변한다. 벡터끼리 같은 모양을 가지면 덧셈, 뺄셈, 성분곱이 가능하다.
노름(Norm) : 원점으로부터의 거리. L-1 노름은 각 성분의 절댓값을 모두 더해 계산하고, L-2 노름은 유클리드 거리를 통해 계산한다.
내적 : 한 벡터와 그 벡터를 향해 정사영된 벡터 길이의 곱.
AI Math 2
행렬 : 벡터를 원소로 가지는 2차원 배열. 행(row)과 열(column)이라는 인덱스를 가진다. 공간에서 여러점을 나타낸다. 행벡터 xi 는 i번쨰 데이터를 의미한다. 행렬끼리 같은 모양을 가지면 덧셈, 뺄셈, 성분곱이 가능하다.
행렬 곱셈(matrix multiplication) : i 번째 행벡터와 j 번째 열벡터 사이의 내적을 성분으로 가지는 행렬을 계산. 행렬을 벡터 공간에서 사용되는 연산자로 이해하면 행렬곱을 통해 벡터를 다른 차원의 공간으로 보낼 수 있으며, 패턴을 추출하고 데이터를 압축할 수도 있다.
역행렬(Inverse matrix) : 어떤 행렬의 연산을 거꾸로 되돌리는 행렬. 정사각행렬이며 행렬식이 0이 아닐 때만 계산할 수 있다. 역행렬을 계산할 수 없다면 유사역행렬을 이용한다.
AI Math 3
경사상승법(gradient ascent) : 미분값을 더하여 함수의 극댓값의 위치를 구할 때 사용한다.
경사하강법(gradient descent) : 미분값을 빼 함수의 극소값의 위치를 구할 때 사용한다.
*벡터가 입력인 다변수 함수의 경우 각 변수를 편미분한 그레이디언트(gradient) 벡터를 이용하여 경사하강/상승법에 이용한다.
AI Math 4
확률적 경사하강법(Stochastic gradient descent) : 모든 데이터를 사용해서 패러미터를 업데이트하는 대신 데이터 한 개 또는 일부(미니 배치)를 활용하여 업데이트. 볼록이 아닌 목적식은 sgd를 통해 최적화할 수 있다. 또한 연산자원을 효율적으로 활용하는데 도움이 된다.
AI Math 5
softmax 함수 : 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산. 분류 문제를 풀 때 선형모델과 소프트맥스 함수를 결합하여 예측한다.
신경망 : 선형모델과 활성함수(activation function)을 합성한 함수. 다중 퍼셉트론(MLP)은 신경망이 여러층 합성된 함수이다.
역전파(backpropagation) 알고리즘 : 각 층 패러미터의 그레디언트 벡터를 윗층부터 역순으로 계산. 합성함수 미분법인 연쇄법칙을 기반으로 자동미분을 사용한다.
AI Math 6
이산형 확률변수 : 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링한다.
연속형 확률변수 : 데이터 공간에서 정의된 확률변수의 밀도 위에서의 적분을 통해 모델링한다.
기댓값(Expectation) : 데이터를 대표하는 통계량이면서 동시에 확률분포를 통해 다른 통계적 범함수를 계산하는데 사용. 기댓값을 이용해 분산, 첨도, 공분산 등 여러 통계량을 계산할 수 있다.
몬테카를로 샘플링 : 확률분포를 모를 때 데이터의 기댓값을 계산하는 방법으로, 이산형이든 연속형이든 상관없이 적용 가능하다. 독립추출만 가능하다면 대수의 법칙에 의해 수렴성을 보장한다.
AI Math 7
모수적(pramtic) 방법론 : 데이터가 특정 분포를 따른다고 선험적으로 가정한 후 그 분포를 결정하는 모수를 추정하는 방법.
비모수적(nonparametic) 방법론 : 특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의개수가 유연하게 바뀌는 경우.
최대가능도 추정법(MLE) : 이론적으로 가장 가능성이 높은 모수를 추정하는 방법. 데이터 집합 X가 독립적으로 추출되었을 경우 로그 가능도를 최적화한다.
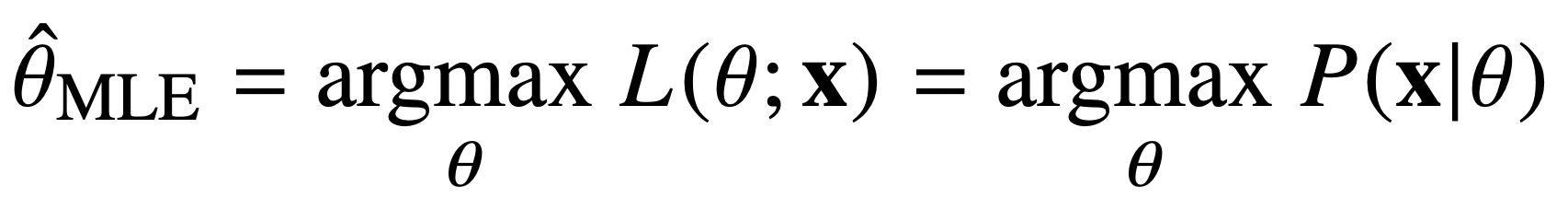
AI Math 8
베이즈 정리 : 조건부 확률을 이용해 정보를 갱신하는 방법. 새로운 데이터가 들어왔을 때 앞서 계산한 사후확률을 사전확률로 이용하여 갱신된 사후확률을 계산할 수 있다.
인과관계(casuality) : 데이터 분포에 강건한 예측모형을 만들 때 필요하다. 인과관계를 알아내기 위해서는 중첩요인(confounding factor)의 효과를 제거하고 원인데 해당하는 변수만의 인과관계를 계산해야한다.
AI Math 9
Convolution 연산 : 커널(kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조. 신호를 커널을 이용해 국소적으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것이다. 커널은 정의역 내에서 움직여도 변하지 않고 주어진 신호에 국소적으로 적용한다. Convolution연산은 커널이 모든 입력데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution연산이 나오게된다.
AI Math 10
시퀀스(sequence) 데이터 : 소리, 문자열, 주가 등의 순서가 의미를 가지는 데이터. 시퀀스 데이터는 독립동등분포(i.i.d.)가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다.
RNN : 가장 기본적인 RNN모형은 MLP와 유사한 모양이다. RNN은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링하며, RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산한다. 이를 Backpropagation Through Time(BPTT)이라 한다. 또한 vanilla RNN의 경우 시퀀스 길이가 길어지는 경우 BPTT를 통한 역전파 알고리즘의 계산이 불안정 해지므로 길이가 긴 시퀀스를 처리하는데에 문제가 있고, 이를 해결하기 위해 등장한 RNN 네트워크가 LSTM과 GRU이다.
과제 수행 과정 및 결과
필수 과제의 경우 기본적인 파이썬 문법을 활용하면 풀 수 있는 문제들이었기에 수행하는 데에 큰 어려움은 없었다. 매 피어세션마다 서로의 코드를 리뷰하는 시간을 가졌는데, 이 시간을 통해 정규표현식의 유용함을 깨달을 수 있었고 공부해야겠다는 생각을 했다!
선택 과제의 경우 필수 과제에 비해 심화된 내용을 다루었는데, 특히 선택 과제 1번을 수행하고 조원들과 코드 리뷰를 진행하면서 원리를 파악하고 코드를 짜는 것과 그렇지 않은 것의 차이가 명확히 드러남을 깨닫고 반성할 수 있었다. 머신러닝에서 기초와 개념이 중요한 이유를 직접 경험한 순간이었다.
피어 세션
우리 피어 세션 조의 경우 매일 강의 및 과제 진도 공유, 강의 내용 중 이해하기 어려웠던 부분 질문, 과제 코드 리뷰, 익일 공통 목표 수행량 설정 등의 활동을 진행하고 있다. 그 외에도 이번 주 수요일에 있었던 '피어 세션이 피었습니다' 활동 준비를 같이 하는 등으로 시간을 활용했다. 마크다운 문서 작업의 유용함을 직접 HackMd를 사용하며 경험하기 시작했다.
학습 회고
정신없이 지나간 한 주였다. 지식의 측면에서나 ai를 바라보는 시각적인 측면에서나 지난 주와는 크게 달라졌음을 느끼고 있다. 정말 멋지고 대단하신 분들이 마스터로, 멘토로, 또 피어로 계셔서 큰 동기부여가 되는 점이 너무나 좋고, 특히나 열정있게 공부를 이어나가는 조원분들께조금이라도 도움이 되고자 더욱 열심히 따라가야겠다는 생각이 든다. 이번 주는 내 학습에 관해서는 깊게 짚어보지 못한 점이 아쉬워 다음주부터는 보완해야겠다. 하루하루 발전할 수 있는 이 순간을 즐기자.
'Boostcamp AI Tech 2기' 카테고리의 다른 글
부스트캠프 ai tech 2기 7주차 학습 정리 노트 (0) 2021.09.15 부스트캠프 ai tech 2기 6주차 학습 정리 노트 (4) 2021.09.10 부스트캠프 ai tech 2기 4주차 학습 정리 노트 (0) 2021.08.27 부스트캠프 ai tech 2기 3주차 학습 정리 노트 (0) 2021.08.20 부스트캠프 ai tech 2기 2주차 학습 정리 노트 (0) 2021.08.13