-
부스트캠프 ai tech 2기 7주차 학습 정리 노트Boostcamp AI Tech 2기 2021. 9. 15. 14:48

강의 복습
7강 Transformer (1)
Transformer : 기존의 seq2seq with attention 모델에서 add-on 모듈로 사용되었던 attention 개념만을 사용해서 RNN 부분을 통째로 대체할 수 있게 만든 모델.
Query, Key, Value :
seq2seq with attention에서 context 벡터를 만들었던 과정을 떠올려보자. decorder의 특정 time step에서의 hidden state 벡터와 encoder의 hidden state 벡터를 내적한 값들에 sofrmax를 취해 가중치 배열을 만들었고, 이 가중치들을 이용해 encoder의 hidden state 벡터들의 가중평균을 구해 context 벡터로 사용했다.
이와 비슷한 과정을 transformer도 적용하게 되는데, 각 단어의 Input 벡터가 각기 다른 weight와 곱해져 decorder의 hidden state 벡터와 encoder의 hidden state 벡터 역할을 모두 수행하는 것이다. 특정 단어의 Input 벡터에 W_Q 행렬을 곱하면 decorder의 특정 time step에서의 hidden state 벡터 역할을 하는 Query가 되고, 모든 단어의 Input 벡터에 W_K 행렬을 곱하면 encoder의 hidden state 벡터 역할을 하는 Keys가 된다. 이 특정 단어의 Query를 Key들과 내적하고 각 key의 길이인 d_k의 루트로 나눠준 후 softmax를 취해 가중치 배열을 만드는 것이다. 여기서 루트 d_k를 사용하는 이유는 d_k가 커질수록 분산이 커져 softmax 결과가 극단적으로 나오게 되기 때문에 쿼리, 키의 차원과 관계없이 표준편차가 같게끔 scaling 해주는 것이다. 이제 이 가중치들을 이용해 모든 단어의 Input 벡터에 W_V 행렬을 곱한 Values를 가중평균내면 특정 단어의 encoding 벡터를 구할 수 있는 것이고, 이 과정을 모든 input 단어에 적용하게 된다.
이러한 과정을 적용하면 유사도가 큰 두 단어 사이의 거리가 멀다고 하더라도 내적에 의한 유사도만 높다면 멀리 있는 정보를 손쉽게 가져올 수 있게 되는, 기존의 RNN이 가졌던 한계점을 극복하는 장점을 가진다. 위의 과정을 수식으로 나타내면 아래와 같다.
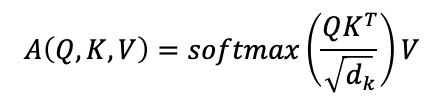
8강 Transformer (2)
Multi-Head Attention : 동일한 시퀀스가 주어졌을 때에도 특정한 쿼리 단어에 대해 서로 다른 기준으로 여러 측면의 정보를 가져와야할 필요가 있을 수 있다. 그러한 정보를 모두 담기위해 다른 가중치를 사용해 여러번 어텐션 학습을 진행하게 된다. 각각의 어텐션 결과들을 하나의 행렬로 concat한 후 입력 벡터와 같은 차원으로 선형변환해주는 것이다. 이 과정을 수식으로 나타내면 아래와 같다.

Residual connection : 출력 벡터를 그대로 반환하지 않고 입력벡터와의 합을 취한 후 반환. 합 연산을 하기 위해선 입력과 출력 벡터의 크기가 같아야한다.
Layer normalization : 각 단어의 인코딩 벡터의 합을 0, 표준편차를 1로 만들어 주는 변환을 한 후, 여러 단어에 대해 각 노드별로 Affine transformation(y = ax+b꼴의 변환)을 수행한다.
Positional Encoding : 각 단어의 문장에서의 위치를 고려해 encoding을 수행하지 않으면 A hits B 와 B hits A의 각 단어는 정확히 같은 encoding 벡터 output을 가질 것이다. 따라서 위치별로 특정한 벡터를 더해줘 위치 특성을 가르쳐주게 된다. 논문에서는 이 특정 벡터로 sin과 cos을 번갈아가며, 또 주기를 바꿔가며 사용한다.
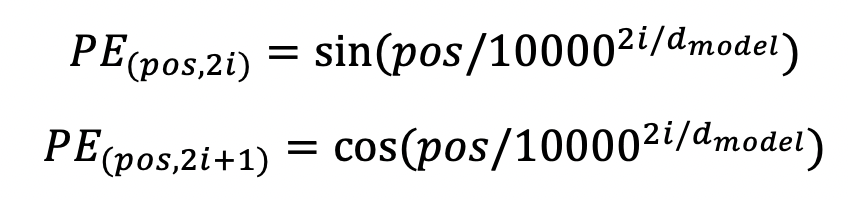
Decoder of Transformer : decoder의 Masked Multi-head Attention과 Add&Norm을 모두 거친 단어들을 쿼리로 변환하고 encoder에서 온 encoding 벡터들을 키와 밸류로 변환해 Multi-head Attention과 Add&Norm, Feed Forwad, Linear transform을 진행한다.

Architecture of Transformer Masked Self-Attention : 디코딩 단계의 학습에서 쿼리, 키의 내적을 이용해 밸류 벡터들의 가중평균에서의 가중치를 결정할 때, 아직 나오지 않은 다음 단어를 이용해 학습을 진행하는 것을 방지하기 위해 이전 단어의 쿼리로 이후 단어의 키를 내적 연산한 값을 모두 음의 무한으로 바꿔준 후 softmax를 적용한다. (강의에서는 모든 sofrmax 연산을 정상 진행 후 해당 부분을 0으로 바꿔주고 나눗셈연산을 통해 각 쿼리별 행의 합을 1로 맞춰주는 작업을 진행해준다고 설명했다.)

9강 Self-supervised Pre-training Models
Self-supervised Pre-training Models in NLP : 정답지가 필요없는 다음 단어 예측을 수행하는 Language modeling 등의 task로 Self-supervised learning을 충분히 시켜 Pre-trained Model을 구축하고 이후 label이 필요한 소규모 데이터를 학습시킬 때 위의 모델을 불러와 layer를 추가해 transfer learning을 진행하게 된다.
GPT-1 : Language modeling task를 통해 Pre-training을 진행하여 다양한 special tokens를 이용해 자연어 처리에서의 많은 task들을 동시에 커버할 수 있는 통합된 모델.

GPT-1의 각 task별 special tokens 활용 BERT :
- Masked Language Model : 기존의 language modeling task를 이용한 Pre-training 과정에선 맞춰야하는 단어의 왼쪽 혹은 오른쪽만 보고 학습과 예측 과정을 수행했다. 양방향을 이용하는 것이 좋을 것 같다는 motivation에서 bert는 각 단어를 15%정도의 확률로 masking하고 주변의 단어를 통해 masked된 단어를 맞추는 Pre-training 과정을 거치게 된다. 특히, 그 15% 중에서도 10%는 random word로 바꾸고 10%는 정답을 그대로 주어 다른 단어로 바꾸어야하는지, 그대로 두어야하는지도 학습을 하게 해 Pre-training 과정 이후 다른 task를 수행할 때도 범용적으로 학습을 잘 수행하도록 한다.
- Next Sentence Prediction : 문장 레벨에서의 task에 대응하기 위해 제안된 Pre-training 기법. 두 개의 문장을 [SEP] 토큰을 이용해 하나의 문장으로 이어주고 끝에도 [SEP] 토큰을 붙여준다. 그리고 맨 앞에는 [CLS] 토큰을 붙여 GPT에서 Extract 토큰이 문장에서의 예측 task를 수행할 수 있도록한 것과 비슷한 역할을 하도록 한다. [MASK] 토큰 또한 사용되며, 두 문장의 관계가 이어지는 문장인지 아닌지를 Label로 하여 학습하는 것이다.

- Segment and position embeddings : bert에서는 마치 word2vec처럼 기학습된 position embedding 방법을 사용하며, 하나로 합쳐진 두 문장이 서로 다름을 나타내기 위해 속해있는 문장에 따라 embedding 벡터를 합하는 segment embedding 과정을 거친다.

Input Representation of BERT 10강 Advanced Self-supervised Pre-training Models
GPT-2 : Language modeling task를 통해 Pre-training을 진행한 점은 전작과 같다. 40GB의 양질의 대용량 text를 이용해 학습하였으며, 다양한 task를 parameter나 architecture modification없이, 즉 zero-shot setting으로 수행할 수 있게 되었다. 이러한 학습 방식은 모든 task를 Question Answering방식으로 치환(Multitask Learning as Question Answering)하여 생각한 연구 사례인 The Natural Language Decathlon에서 착안하였다고 한다. 또한 Byte pair encoding (BPE)이라는 subword 수준의 word embedding을 도출해 사전을 구축할 수 있는 알고리즘을 사용했다.
GPT-3 : 전작에 비해 비교할 수 없을 정도로 많은 패러미터 수, 학습 데이터, 배치사이즈를 사용해 성능을 높인 모델. 또한 전작의 Zero-shot과 달리 Few-shot Learners를 사용하는데, 이는 내부 구조의 변형 없이 추론 과정에서 몇 개의 예시를 관찰하여 성능을 향상시키는 방법이다. 또한 큰 모델을 사용할수록 Few-shot의 성능이 커지는 경향을 보인다.

ALBERT : 모델의 사이즈와 학습시간은 줄이고 성능은 향상시킨 개선 모델.
- Factorized Embedding : 초기의 단어별 임베디드 벡터는 상수의 역할을 하므로 임베딩 레이어의 사이즈를 줄여 계산량을 줄인다.
예를 들어 500x100 사이즈의 임베디드 행렬을 500x15로 줄이고 15x100 사이즈의 원본 크기로 되돌리는 행렬W를 둔다면 학습해야할 패러미터 수는 500x100에서 500x15+15x100으로 줄어든다.

- Cross-layer Parameter Sharing : 각 attention 블럭별로 다른 패러미터를 가지지 않고 공유하도록 한다. feed-forward network만 공유하거나 attention parameters만 공유하거나 모두 공유하거나 모두 공유하지 않는 경우를 비교했을 때, 공유를 할 수록 파라미터와 학습속도는 줄지만 성능 면에서는 큰 차이가 없는 결과를 보였다고 한다.
- Sentence Order Prediction : Next Sentence Prediction pretraining task가 너무 쉽고 실효성이 없다는 기존의 문제가 있었다. 그래서 연속된 두 문장의 순서가 바뀌었는지 여부를 예측하는 것으로 난이도를 올려 유의미한 성능 변화를 보였다.
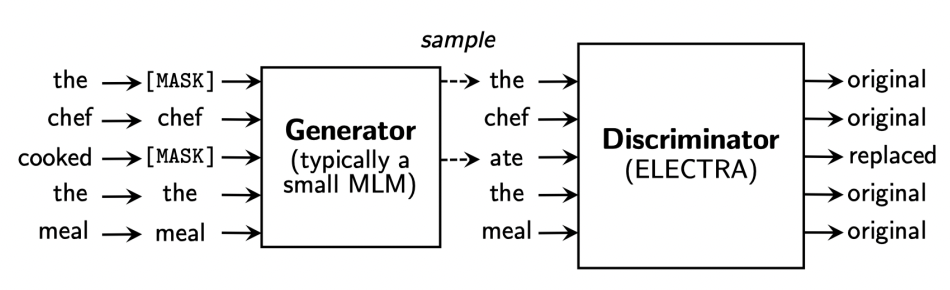
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately): 기존의 마스크 처리된 단어들을 맞추는 작업을 generater에서 수행하고, 그 결과물로 나온 단어들을 기존에 있던 단어인지, 마스크 처리된 것을 대체한 것인지를 맞추는 task를 수행하는 Discriminator를 둔다. 이는 GAN에서의 기법에서 착안한 방법으로, 최종적으로 pre-trainied model로 Discriminator를 사용하게 된다.
과제 수행 과정 및 결과
이번 주는 지난 주에 대부분의 과제를 해서 그런지 수행해야할 과제가 적었다. 그러나 이번 주에도 주어진 task만 수행하였고, 전반적인 코드 이해 과정을 진행하지 못한 것이 무척 아쉽다. 연휴간 보완해야겠다.
피어 세션
이번 주를 마지막으로 두번째 팀과의 피어세션 시간이 끝을 맺었다. 2주라는 짧은 시간이었지만 그 새 팀원들과 정이 많이 들었기에 아쉽다. 특히 범찬님과 Word2vec을 읽고 발표한 것이 기억에 크게 남는데, 논문 읽기의 두려움을 없애고 즐거움을 찾을 수 있었던 시간이었다. 연휴기간을 이용해 이해한 내용을 간략하게나마 이 블로그에 정리해야겠다.
그 외에 또 기억에 남는 것은 마지막 피어세션 시간에 상민님이 '다인님 덕분에 저희 조 분위기가 밝았던 것 같습니다'라고 말해주신 것이었는데, 내가 갖가지 몰이(?)들을 당하면서도 그런 몰이들을 나부터 즐기고 또 유쾌하게 반응하다보니 이러한 최고의 칭찬을 들은 것이 아닌가 싶다. 협업에서 팀의 분위기를 좋게 만드는 것은 매우 중요하다고 생각하는데, 그 역할을 나의 이러한 면이 해낼 수 있구나를 알게되어 무척이나 뿌듯하였다.
이번 피어세션 팀에선 유능한 팀원분들과 함께 깊게 생각하는 연습과 나의 생각을 조리있게 말하는 연습을 할 수 있었고, 그들의 유쾌하면서도 자기 생각을 말할 땐 자신감있는 태도를 보고 많은 것을 배울 수 있었다. 이번 팀과는 매월 마지막 금요일에 1시간의 피어세션을 가지기로 했기에 다음주 금요일이 더욱 기대가 된다.
학습 회고
이번 주는 연휴를 앞두고 있어서 그런지 들뜬 마음을 완전히 억누르진 못한 것 같아 아쉽다. 그럼에도 기초 개념의 중요성과 누군가 이렇게 묻는다면 나는 어떻게 답할까?와 같은 끊임없는 물음표를 던져가며 transformer 개념 공부를 했기에 만족스러운 한 주였다. 기초가 중요함을 계속 상기하고 물음표를 던져가며 공부하는 방법을 앞으로도 쭉 익히자. 이번 주도 고생많았다!
'Boostcamp AI Tech 2기' 카테고리의 다른 글
부스트캠프 ai tech 2기 9주차 학습 정리 노트 (0) 2021.10.01 부스트캠프 ai tech 2기 8주차 학습 정리 노트 (0) 2021.09.24 부스트캠프 ai tech 2기 6주차 학습 정리 노트 (4) 2021.09.10 부스트캠프 ai tech 2기 4주차 학습 정리 노트 (0) 2021.08.27 부스트캠프 ai tech 2기 3주차 학습 정리 노트 (0) 2021.08.20